PublicationsList integration with DSpace
You can use a local installation of PublicationsList.org as a way for researchers to gather details of their papers for automatic harvesting by a local DSpace repository. Researchers can select which collections in the repository they would like their work archived, and the harvester automatically sends the metadata and full text to the appropriate workflow queues (or direct into the live repository if no approval step has been added for the collection). Duplicates are detected, so if several co-authors add the same paper, it is only entered once into the repository, and all publications lists will link out to the same copy. Please contact us if you are interested in something similar for other repository systems.
- 1. Download and install the harvesting module
- 2. Configure the harvesting settings
- 3. Update the list of collections
- 4. Configure publicationslist for harvesting
- 5. Running the harvester
1. Download and install the harvesting module:
The DSpace harvesting code uses the standard batch importer supplied with DSpace (ItemImporter). This means that no changes are needed to your DSpace installation to use it.
The harvesting code is in PHP and should be run from the command line as the dspace user. It checks with your local installation of PublicationsList.org for any recently updated lists, and imports full text items into the appropriate collections in the repository. The harvested items are added to the standard workflow queue (if the dspace collection has an approval step), so can undergo checking by library staff before being made public.
You can download the code from:
It needs to be run as the admin user of the DSpace installation, so:
The harvest utilities are in PHP, and run from the command line, so you need the command line version of PHP installed (you may need to install a package like 'php-cli' or 'php5-cli') The files are:
2. Configuring the DSpace harvester
The dspace harvester needs to know the URL of the publications list feed and the DSpace installation. The settings are in a file harvest/config.inc.php, a sample is provided in config.inc.sample
The configuration settings are listed below - you need to edit them to match your installation. The harvester will submit all items as the $dspaceuser - this should be a dspace account with permission to submit to any collection (you could use the admin account or create a special dspace user for the harvester).
2.2 Supporting additional dublin core metadata fields
The publicationslist schema is based on bibtex and includes more fields than the basic dublin core included as standard with a DSpace installation. However, it is possible to add extra fields to DSpace, e.g. using the Registries - Metadata - dcmi terms dspace web interface. If you do this, you can add extra mappings from publicationslist fields to the new dublin core field names by setting an '$extradcfields' array in the config.inc.php file, e.g.:
N.B. the target field names (e.g. 'dc.identifier.doi') must have been added to your dspace metadata registry first, or the dspace importer will report that the field name is unknown.
3. Updating the list of collections
Users can choose the collection(s) in the repository where their publications should be archived. The list of collections is supplied in a tab separated text file stored in your publications list installation directory: php/collections.txt which includes the hierarchy of communities and collections.
The format of lines used for 'communities' (e.g. department names) is: {community name}\t{repository id}\n - for 'collections' it is: {collection name}\t{repository id}\tcollection\n. Hierarchy is represented using the appropriate number of tabs before the first name, e.g.:
A sample is included in publist/php/collections-sample.txt and you could copy this to publist/php/collections.txt Note that this sample includes dummy collection IDs (like 1234/567) - so users would be able to pick a collection, but the repository would only harvest items with collection IDs it recognises.
The hierarchy of collections with their IDs is already available in your DSpace installation, e.g. http://dcommon.bu.edu/xmlui/community-list and a utility is available for extracting the hierarchy from this web page - the information has to be scraped from the HTML as it is not available via the DSpace implementation of the OAI-PMH ListSets call (which just returns a flat list without distinguishing between 'communities' and 'collections').
A variant is also included for DSpace 1.5.x installs; php list-dspace15-collections.php - you'll need to edit the URL of your DSpace install at the top of this file as the sample points to the BU installation.
You will need to regenerate the collections.txt file each time new collections are added to the DSpace install. You can also edit the file by hand if you do not want particular collections to be available for selection by publications list users.
3.1. Switch on the collections feature in PublicationsList
To switch on the collections feature in the PublicationsList user interface, you need to edit the following settings in the publist/php/config.tmp file of your local installation - and make sure that there is a 'php/collections.txt' file with the list (see section above). For the $trackbackCode setting, you need to use the same value as in section 2 above --- you shouldn't use the example value though.
At this point you should be able to log in to your publications list user interface and edit or add a reference; a link to list all available collections is shown next to the 'Full text' area of the reference editing screen:
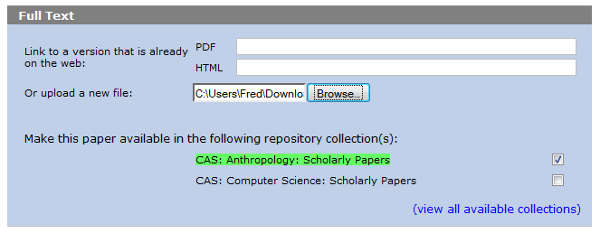
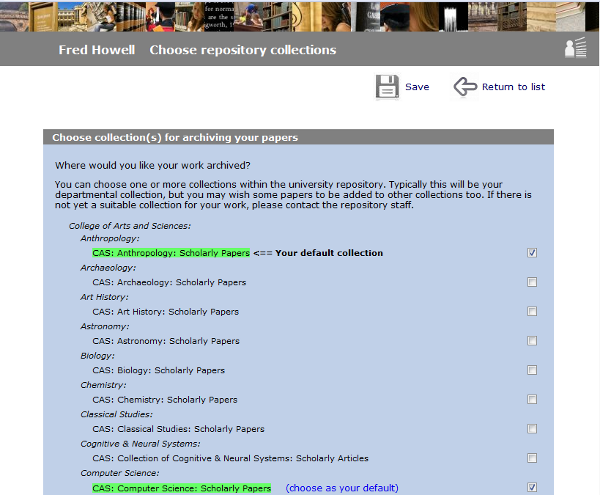
Each user can choose which collections they want to use from the list of all available in the repository, using the '(view all available collections)' link shown in the full text area of the reference editing page. A default collection can also be set which will be selected for all new uploads:
5. Running the DSpace harvester
You can run the DSpace harvester from the command line as the 'dspace' user:
This does the following steps:
- 1. OAI-PMH query of the local DSpace to build up a cache of accepted items and their repository IDs.
- 2. Checks with the publications list for new items. For each item, fetches the metadata and full text, and submits it to the appropriate collection(s) using the DSpace batch importer.
- 3. Runs another OAI-PMH query on the local DSpace in case any items have gone immediately into the live repository. If so, calls a trackback on the publications list to add a link back to the repository copy.
The log output is written to the command line, and should be helpful for debugging if anything is wrong with the setup.
5.1. Testing the harvester
To test the harvester, first add a harvestable publication to a publications list:
- 1. Log in to a publicationslist account
- 2. Add or import a new reference, attach the full text version and choose a repository collection.
- 3. Press the 'publish' button.
... then login as the dspace user and run the harvester from the command line. ( php import.php ) You should see a sequence of log messages as it fetches the publication, runs the dspace importer, and does an OAI-PMH check on the repository for the status of the deposited items. If you refresh the publicationslist page and expand the reference you just added, you should see it reporting that the item has now been harvested and is being checked by repository staff.
You can now log in to DSpace as an admin user, check the 'submissions' page for the new item, and approve it for entry into the repository. The link to the repository copy will be added to the publicationslist entry the next time the import.php script is run - so run php import.php once more and check that it reports calling the trackback OK. At this point there should be a 'Repository' link next to the publicationslist entry if you refresh the edit page.
5.2 Setting up an automated CRON task
The harvester can be set up as a cron task to import any new items automatically. You can set this task to run overnight - in this case, new publications list items will be available in the repository queues the next day - or you could run every few minutes if you want items to be available in the repository more rapidly. A bash script is provided which runs the harvester and outputs any messages to a log file. You should check this works from the command line first, e.g.:
To set this up running regularly, edit the crontab to run the 'do_harvest.sh' bash script - e.g. at 4am each day. The output logs should be written to harvest/cache/log/import_{date}.txt. To run every 10 minutes, replace "00 04" with "*/10 *" below.